どうもお久しぶりです。BASEビール部部長の氏原です。最近急に涼しくなりましたね。ハイアルなベルギービールでも飲んで温まるといい季節ですよ。
さて、今回もビールの話はとりあえず置いておいて現在Data Storategy Groupで取り組んでいる内容として、今年に出たらしい論文「Adversarially Learned One-Class Classifier for Novelty Detection」を実装して商品画像フィルタにならないか試してみたことについてお話しようと思います。
One-Class Classifierとはあるクラスに属するか否かの判別器です。例えばある画像に写っているものがQRコードか否かとか、水着か否かとかです。
今回の話は一行で言えば、ショッピングアプリ「BASE」の商品検索などから意図と異なる画像をフィルタリングするためにAdversarially Learned One-Class Classifier(ALOCC)が使えないか試したという内容です。

背景
皆さんショッピングアプリ「BASE」を使ったことはおありでしょうか?数多くの商品が並んでいて、私は米とか肉とか買ってます。そんな中こんな商品たちを見かけたことはないでしょうか?

またはおすすめショップのところのこういうのとか

こちらは、お知らせをひとつの商品として登録するとこのように表示されます。本来的な商品画像の使用法とは異なりますが、登録自体は可能です。
これらの商品ではない商品がショップのページに出てくるのは特に問題ないのですが、もし検索とかで出てきたら探している商品と違うなぁと思ってしまうのではないでしょうか?
この問題を解決するために商品ではない商品を自動で発見して検索等には出ないようにする機能を開発しています。そしてQRコード画像については現在検索等からの除外を開始しています。
今回お話するのはお知らせ等の文字画像の検出について今取り組んでいることの紹介です。
Adversarially Learned One-Class Classifier(ALOCC) for Novelty Detectionについて
単純に文字画像か否かの判別器を作ることを考えると以下のような問題があります。
- 文字画像ではない画像、という教師データをどう集める?
- 文字画像以外の画像では幅が広すぎる
- 文字画像とはなにか?がはっきりとわからない。人によって違う。
- 文字中心のポスターや、文字っぽいロゴや、サイズ表はどう扱うべきか
- そもそも文字画像のサンプルが少ない
- 圧倒的に教師データが不足している
これらの問題がAdversarially Learned One-Class Classifier for Novelty Detectionでは軽減できそうだったので、使えそうかどうか試してみました。
実験結果に行く前にこの手法を簡単に解説しておきます。
ネットワーク構造
論文に乗ってた画像そのまま上げます。
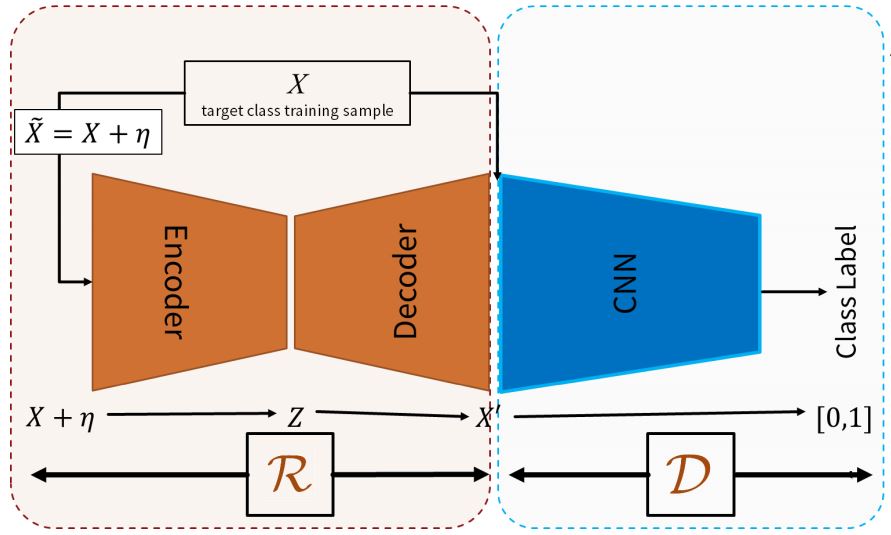
(M Sabokrou, "Adversarially Learned One-Class Classifier for Novelty Detection", arXiv.org, 2018 )
構造としてはGANにインスパイアされたものになります。 D がDiscriminatorなのはGANと同じで、GANでGeneratorだった部分がReinforcerとなっています。ReInforcerは画像(元の画像にノイズを追加したもの)を与えられて、何かしらの画像を出力します。
DiscriminatorはReinforcerが出力した画像と元の画像を見分けるように学習させ、ReinforcerはDiscriminatorを騙すように学習します。
学習の目的
さて、では上記ネットワーク構造は何を意図しているのでしょうか?これは元画像との違いを検出する検出器を作ろうとしているのです。
学習に使う画像は検出したいターゲットのクラスの画像だけ、今回の私の用途で言えば文字画像だけいいのです。文字画像以外の画像というものを教師として揃える必要がありません。これはありがたいです。 教師を作るためにこれは文字画像、これは文字画像ではない…と延々とやってるとこれはどっちだろうかという画像が出てきてだんだん混乱してきます。なのでこれは文字画像にしたいなってものを集めるだけでいいのはとても楽です。
R はターゲットに似た画像を生成するようになります。でも特定のターゲットクラスの画像しか学習してないので、ターゲットのクラスではない画像を渡すとぐちゃぐちゃな画像が生成される、ということを期待しています。今回は文字画像を学習させるので文字画像っぽいものは綺麗に再構築されるけど、それ以外はぐちゃっとなってほしいというわけです。
D は再構築された画像、つまりターゲットから少しでも違う画像を見分けようとするため、違いに敏感になるように学習されます。この結果 D はターゲットとの違い、つまり新規性の検出器となります。 文字画像を1として学習させれば、D が返す結果が1に近いほど新規性がない、つまり学習した文字画像に近い画像ということになり、0に近いほど新規性の高い見たことがない画像ということになります。

(M Sabokrou, "Adversarially Learned One-Class Classifier for Novelty Detection", arXiv.org, 2018 )
論文ではペンギン画像を学習させています。
画像を R に通した結果、ペンギン画像はペンギン画像として再構築されていますが、ペンギンでない画像はなにか汚い画像になっています。この再構築した画像を D に渡すと元の画像を渡すよりも綺麗にペンギンとそれ以外を判別できるようになると主張されています。
実装
さて、一応論文の著者の方のgithubはあったのですが、tensorflowがゴリゴリでわかりづらかったのでpytorchを使って実装してみました。
Reinforcer
Reinforcerの中身は受け取った画像をConv2dで畳み込むencoderと、Deconvするdecorderです。GANだとパラメータ受け取ってDeconvしていくだけなので、ここがちょっと違います。
import torch.nn as nn class Reinforcer(nn.Module): def __init__(self): super(Reinforcer, self).__init__() self.encoder = nn.Sequential( nn.Conv2d(3, 64, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(64, 0.8), nn.Conv2d(64, 128, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(128, 0.8), nn.Conv2d(128, 256, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(256, 0.8), nn.Conv2d(256, 512, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(512, 0.8), ) self.decoder = nn.Sequential( nn.ConvTranspose2d(512, 256, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(256, 0.8), nn.ConvTranspose2d(256, 128, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(128, 0.8), nn.ConvTranspose2d(128, 64, 3, stride=1), nn.ReLU(), nn.BatchNorm2d(64, 0.8), nn.ConvTranspose2d(64, 3, 3, stride=1), nn.Tanh(), ) def forward(self, x): x = self.encoder(x) x = self.decoder(x) return x
Discriminator
DiscriminatorはGANと何も変わりません。受け取った画像を畳み込んで全結合層に渡すだけですね。
import torch.nn as nn class Discriminator(nn.Module): def __init__(self): super(Discriminator, self).__init__() self.model = nn.Sequential( nn.Conv2d(3, 64, 3, stride=2), nn.BatchNorm2d(64, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25), nn.Conv2d(64, 128, 3, stride=2), nn.BatchNorm2d(128, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25), nn.Conv2d(128, 256, 3, stride=2), nn.BatchNorm2d(256, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25), nn.Conv2d(256, 512, 3, stride=2), nn.BatchNorm2d(512, 0.8), nn.LeakyReLU(0.2, inplace=True), nn.Dropout2d(0.25), ) self.adv_layer = nn.Sequential( nn.Linear(512*9, 1), nn.Sigmoid(), ) def forward(self, img): out = self.model(img) out = out.view(out.shape[0], -1) validity = self.adv_layer(out) return validity
学習
学習の仕方もGANとほぼ変わりません。
import torch import torch.nn as nn import torch.optim as optim import torchvision.datasets as dset ... device = torch.device("cuda:0") netR = Reinforcer().to(device) netD = Discriminator().to(device) dataset = dset.ImageFolder(....) dataloader = torch.utils.data.DataLoader(dataset) criterion = nn.BCELoss() optimizerR = optim.Adam(netR.parameters(), lr=..., betas=...) optimizerD = optim.Adam(netD.parameters(), lr=..., betas=...) ... for epoch in range(n_epochs): for data in dataloader: images = data[0] # dset.ImageFolderのtransformでtorchvision.transforms.Lambdaつかって # 元画像とノイズ画像両方とれるようにごにょごにょしてる real = images["real"].to(device) # 元画像 noised = images["noisy"].to(device) # ノイズかけた画像 batch_size = real.size(0) ############################ # Update D network ########################### netD.zero_grad() # 本物 label = torch.full((batch_size,1), 1, device=device) output = netD(real) errD_real = criterion(output, label) errD_real.backward() # 偽物 fake = netR(noised) label.fill_(0) output = netD(fake.detach()) errD_fake = criterion(output, label) errD_fake.backward() optimizerD.step() ############################ # Update R network ########################### netR.zero_grad() # 偽物でDを騙す label.fill_(1) output = netD(fake) errR = criterion(output, label) errR.backward() optimizerR.step()
結果
文字画像を学習させてみた結果、文字画像はそこそこ綺麗に再構築され、それ以外は結構ぐちゃっとなるようになったようです。

| accuracy | false positive | false negative | |
|---|---|---|---|
| D(X) | 0.92 | 0.06 | 0.02 |
| D(R(X)) | 0.87 | 0.03 | 0.10 |
むしろ判別性能はR をかました方が落ちてます。ただ、false positive、つまり本来文字画像じゃないのに文字画像と認識してしまった率は多少改善されました。文字画像は出したくないのですが、本来出したい商品画像が落とされてしまうのは避けたいのでfalse positiveはできる限り抑えたいところです。そういう意味ではそこそこ意味はあるのかなと思います。
感想
- 文字画像はそこまで綺麗にいかない、というか論文の結果の画像が綺麗にできすぎ。何か書いてない(もしくは私がちゃんと読めてない)工夫があるのかも。
- Reinforcerは論文にはない工夫を追加した(まだ実験中なので内容は内緒)。そうしないとただのGANにしかならない。ターゲット画像以外の画像渡しても普通にそこそこ綺麗な画像が再構築される。
- Batch Normarizationは偉大。
まとめ
文字画像を正確に判別できるようになるまではまだまだ道のりが長そうです。 false positive 3%といっても画像は1日に何万枚と上げられてきますので、間違いの絶対数はそこそこ多くなります。理想的には桁をもう一つ下げたいところです。
でも今回の判別器では、単純に文字画像判別器を作ったときに弾かれがちだった文字Tシャツはかなり高精度で文字画像ではなく商品であると認識できるようになりました。
こういうやつ

引き続き良きユーザー体験を提供できるように頑張っていきます。