
この記事はBASE Advent Calendar 2019の4日目の記事です。
こんにちは、BASE BANK株式会社 Dev Divisionに所属している東口(@hgsgtk)です。
普段、ブログやカンファレンスでアウトプットする内容としては、PHP・Go ・Pythonなどサーバーサイド言語を用いた話や、テストやコード設計の話が多いのですが、せっかくの年に一回のアドベントカレンダーなので、普段はあまりしないクラウドインフラのレイヤーの話をしたいと思います。
私は、「YELL BANK(エールバンク)」というサービスの開発・運用をしています。そのサービスの運用にあたって、Relational databaseとして、Amazon Auroraを利用しています。
Amazon Auroraを利用するにあたって、アプリケーションから参照系リクエストを受け付けるエンドポイントを定義するのにCustom endpointを使用しています。
このCustom endpointにおいて、フェールオーバーを想定した場合に必要な、設定のちょっとした注意点を紹介してみます。
ケーススタディ
次のように、1台の書き込みロールのインスタンスと、2台の読み込みロールのインスタンスの計3台のインスタンスがぶら下がるクラスターを想定してみます。
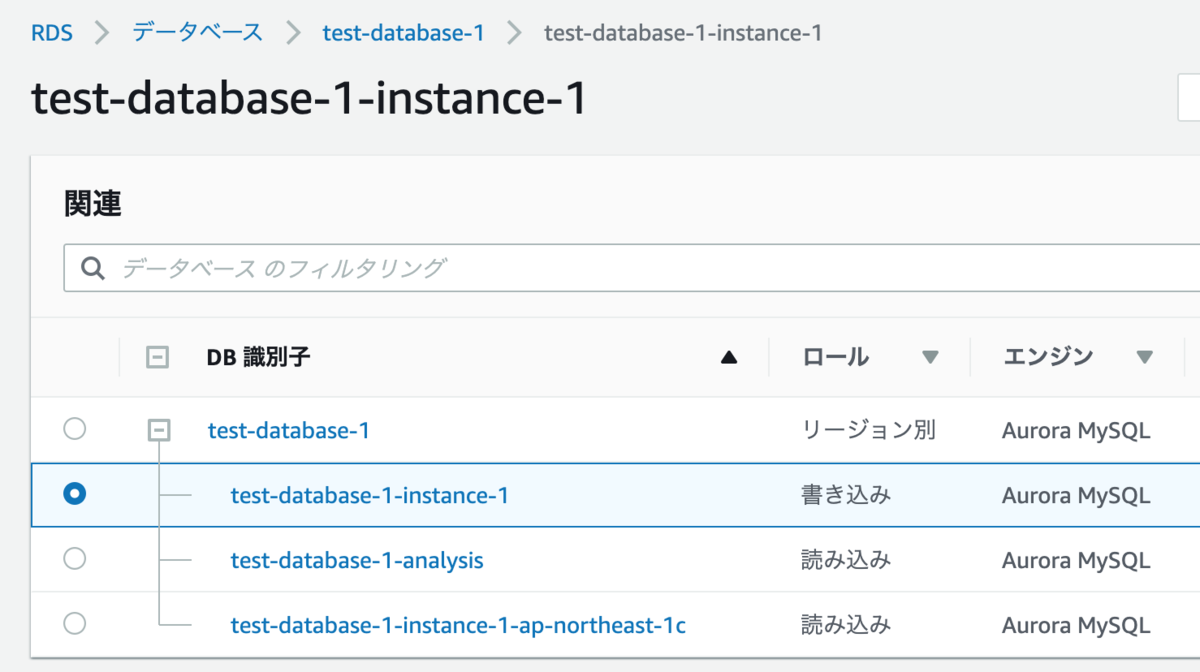
このクラスターにおいて、アプリケーションからはtest-database-1-analysisという読み込みロールのインスタンスは参照せず、分析用として使うという構成だとします。
Amazon Auroraのエンドポイント
前提知識として、Amazon Auroraには4つのエンドポイントが存在します。
まず、現在のプライマリDBインスタンスに接続するクラスターエンドポイント、DBクラスターの使用可能なAuroraレプリカのいずれかに接続する読み取りエンドポイント、Auroraクラスター内の特定のDBインスタンスに接続するインスタンスエンドポイント、そして今回の記事のタイトルでもあるカスタムエンドポイントです。
カスタムエンドポイントは、選択したDBインスタンスのセットを表し、選択したグループ内で負荷分散を行い接続します。
今回のケースでは、読み取りエンドポイントの一部をアプリケーションから使いたいことが要求です。その要求をカスタムエンドポイントであれば叶えられそうです。
カスタムエンドポイントタイプ
実際にカスタムエンドポイントを設定します。ただし、フェールオーバーが起きてインスタンスのロールが入れ替わった際の考慮は忘れてはいけません。そういった場合に知っておくべきはカスタムエンドポイントタイプです。
このカスタムエンドポイントタイプによって、当該エンドポイントに関連づけることができるDBインスタンスが決まります。具体的には、READER・WRITER・ANYの三種類があります。
- READER: 読み取り専用のAuroraレプリカであるDBインスタンスのみが、これの一部になれる
- WRITER: マルチマスタークラスターにのみ適用される、複数の読み書きDBインスタンスを含めることができる
- ANY: 読み取り専用のAuroraレプリカと、読み取り/書き込みのプライマリインスタンスの両方がこれの一部になれる
カスタムエンドポイントタイプは、マネジメントコンソール上で見る限りは、表示されていないので、気がつきにくいですが、マネジメントコンソールで作成した場合には、ANYになります。
カスタムエンドポイントタイプの ANY または READER を AWS マネジメントコンソール で選択することはできません。AWS マネジメントコンソール で作成するすべてのカスタムエンドポイントは ANY タイプになります。
マネジメントコンソールから作ってみると
例えば、マネジメントコンソールで作成したカスタムエンドポイントに、設定時点で読み込みロールのインスタンスを選択してみます。
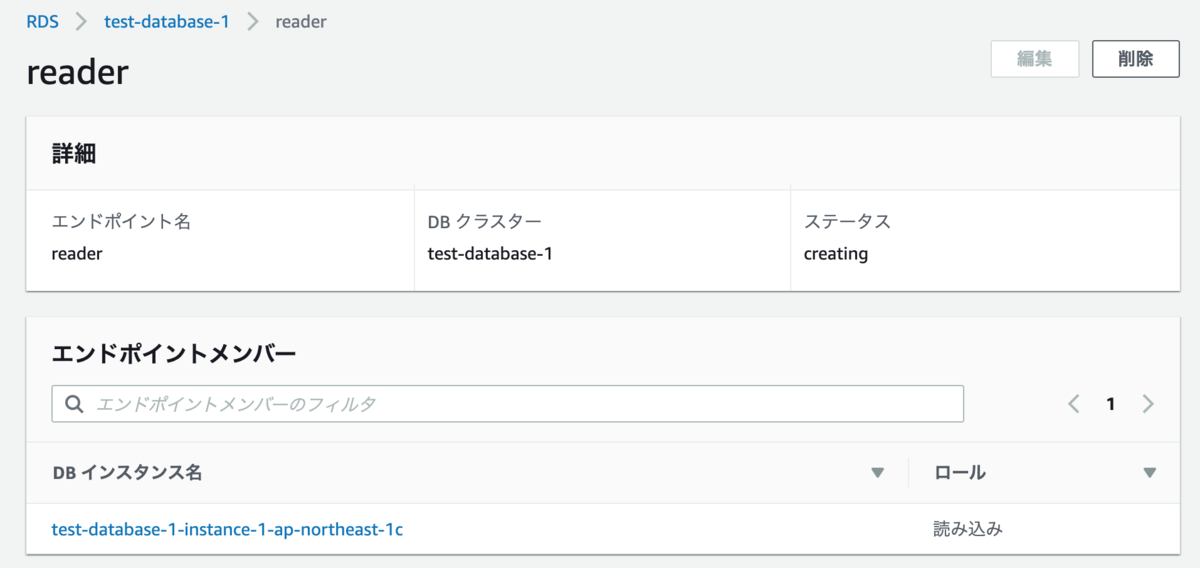
この状態でマネジメントコンソールからフェールオーバーさせてみます。すると、カスタムエンドポイントに設定したインスタンスは次のように変化します。
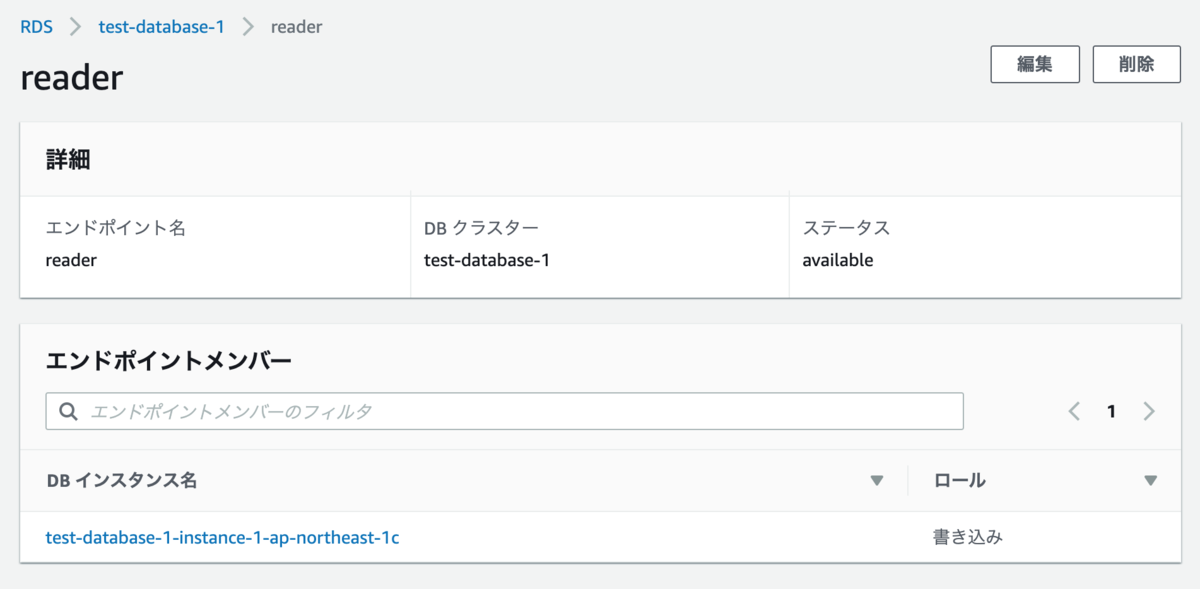
ロールが書き込みになってしまいました。これでは、レプリカのみを参照したいエンドポイントにしたい意図を満たすことができません。
どうすればいいか
先ほどお伝えした通り、現時点(2019年12月4日)で、マネジメントコンソールから、カスタムエンドポイントタイプを設定する方法はなく、デフォルトでANYとなります。しかし、AWS CLIからはカスタムエンドポイントタイプを指定できるので、そちらで作っていきましょう。
AWS CLIでカスタムエンドポイントを作成する場合、create-db-cluster-endpointを使用します。
$ aws rds create-db-cluster-endpoint --db-cluster-identifier test-database-1 \ --db-cluster-endpoint-identifier reader-2 \ --endpoint-type READER \ --static-members test-database-1-instance-1-ap-northeast-1c test-database-1-instance-1
オプションendpoint-typeにてREADERを指定することで、カスタムエンドポイントタイプがREADERになります。
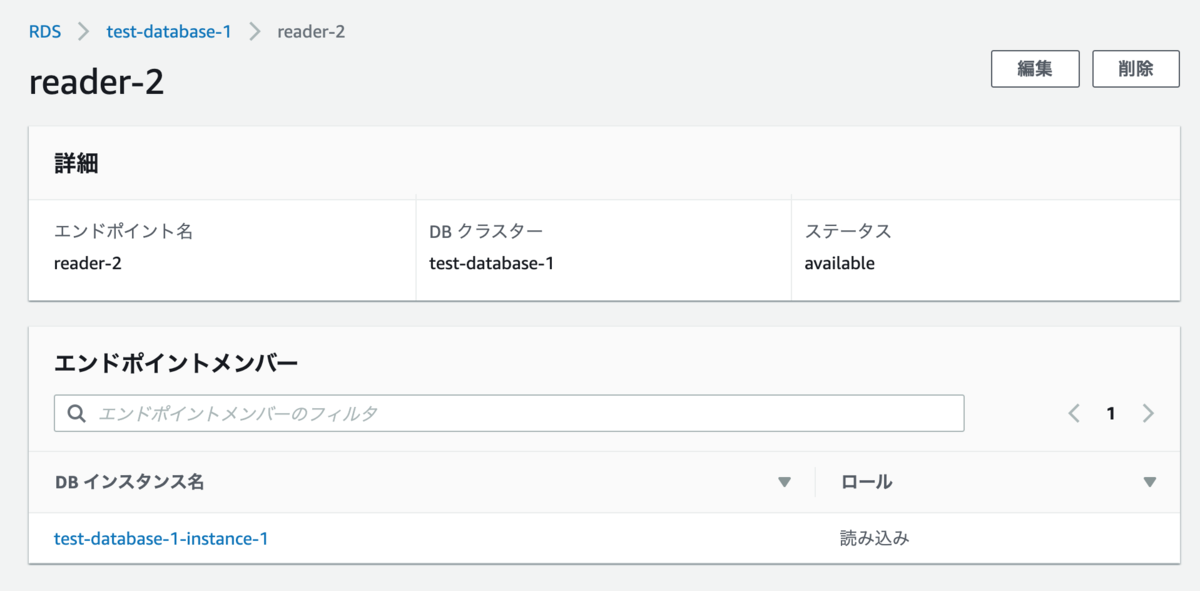
また、この時の設定方法として、設定したい読み込み専用DBインスタンスと、現在のプライマリDBインスタンスの両方を設定しておきます。するとマネージメントコンソールからは次のように見えます。

現在、読み込みロールとなっているtest-database-1-instance-1-ap-northeast-1cのみがエンドポイントメンバーとなっており、プライマリDBインスタンスは読み込み専用ではないのでメンバーにはなっていません。
こうしておくと、フェールオーバーが起きて、書き込み・読み込みが入れ替わった場合においても、読み込み専用のインスタンスに対して解決するようになります。
ちなみに、YELL BANKの運用のためのインフラ構成管理は、基本的にTerraformで行なっていますそのため、Terraformのtfファイルにて次のように設定しました。
resource "aws_rds_cluster_endpoint" "test-database-read" {
cluster_identifier = aws_rds_cluster.test-database.id
cluster_endpoint_identifier = "test-database-read"
custom_endpoint_type = "READER"
static_members = ["test-database-1", "test-database-2"]
}
おわりに
以上、Amazon Auroraのちょっとした小ネタの紹介でした。この他にも、サービスの新規開発時や運用していく中で、クラウドインフラのレイヤーの経験もたまっていっているものがあるので、2020年も小出しにでもみなさまにお届けできればと思います。
明日は、Data Strategyチームの鈴木さんとOwners Growthチームの遠藤さんです!お楽しみに〜!