 この記事はBASE Advent Calendar 2022の19日目の記事です。
この記事はBASE Advent Calendar 2022の19日目の記事です。
はじめに
こんにちは、DataStrategyチームの竹内です。
今回はBASEで作成されたショップが扱っている商品のカテゴリを機械学習モデルを使って推論するための取り組みについてご紹介いたします。
※ 記事内のコードはサンプルとして簡略化しています。
TL;DR
- BASEで作成されたショップに登録されている商品のカテゴリ(ファッション、食料品など)を予測するモデルを作成しました
- 分類モデルにはBERTをファインチューニングしたものを使用しました(商品画像の利用は今後の課題です)
- アノテーションにはAWS Ground Truthを利用しました
- カテゴリ数分の2値分類モデルを作成し、8カテゴリ分をマルチラベルでラベル付けしています
- モデルの学習は社内オンプレGPUマシンを利用し、推論はAWS Batchを利用しています
商品カテゴリ
現在BASEで作成されたショップからはファッションアイテム、インテリア用品、食料品など毎日数万点もの様々な商品が登録され、販売されています。
しかしながら、それら1つ1つの商品がどういったカテゴリに属するかを把握することは容易ではなく、例えば「BASEを通じてどれぐらいファッション商品が販売されたのか」「不正決済が起きている商品の傾向はどういったものか」といった細かい分析を行う際は、人の手で商品を1つ1つ確認していくか、ショップ側で設定されたショップのカテゴリを利用することが多いのが現状です。
ところが、ショップのカテゴリが必ずしもそのショップで販売されている商品のカテゴリと一致するとは限らず、またショップカテゴリの設定は任意であるためカテゴリを設定していないショップも数多く存在します。
そのため、DataStrategyチームではその日にBASEのショップで登録された商品のカテゴリを、機械学習モデルを用いて自動的に推論するバッチ処理基盤を新しく作成しました。
データセットの作成
機械学習モデルを作成するためには学習およびテスト用のデータセットが必要となります。
着手段階では商品のカテゴリが正確にラベル付けされている一定の規模のデータセットが存在しなかったため、まずはそれらの作成から行いました。
ラベルセットの検討
データセットの作成にあたり、まず商品にどのようなラベルをつけていくかの検討を行いました。
基本的には既存のショップカテゴリをベースにしつつ、実際の商品群に目を通しながら、できるだけ漏れや重複が少なくなるよう大カテゴリ8種類(インテリア、ファッション、スポーツ、電子機器、コスメ、飲食物、サービス)と、その下の中カテゴリ約100種類(調理器具、Tシャツ、ゴルフ用品、お菓子など)に整理しました。
その上で一旦大カテゴリ8種類分に絞った分類モデルの作成を行うことにしました。
データのサンプリング
BASEのショップで既に公開されている商品をランダムにサンプリングし、アノテーションを行うことで学習およびテスト用のデータセットを作成しました。
サンプリングする際は特定の季節の商品に偏らないように1年以上幅のある範囲から均等に抽出を行いました。
その上でアノテーションコストを抑えつつ8種類の大カテゴリ全てについて十分なサンプルサイズを確保できるよう、既に十分なサンプルサイズが得られたカテゴリに分類される商品をフィルタリングする処理を入れました。(後述)
AWS Ground Truthを利用したアノテーション
データセットのアノテーションにはAWS Ground Truthのベンダーワークフォースを利用しました。
AWS Ground Truthを利用した理由としては普段からAWSを使用しているため学習コストが小さい点、S3と連携することでデータセットやワークフローの管理が容易である点、ベンダーワークフォースについてはAWSによって品質やセキュリティの手順が事前にスクリーニングされている点などが挙げられます。
アノテーションにはテキストと商品画像両方を判断材料としたかったのですが、Ground Truthで利用できるラベリングツールはテキスト、画像どちらか片方のみに対応したものであったため、あらかじめ商品画像に商品タイトルと商品説明文をキャプションとして付与した1枚の画像を作成し*1、それを対象に1画像のマルチラベル*2分類タスクとしてアノテーションのジョブを作成しました。

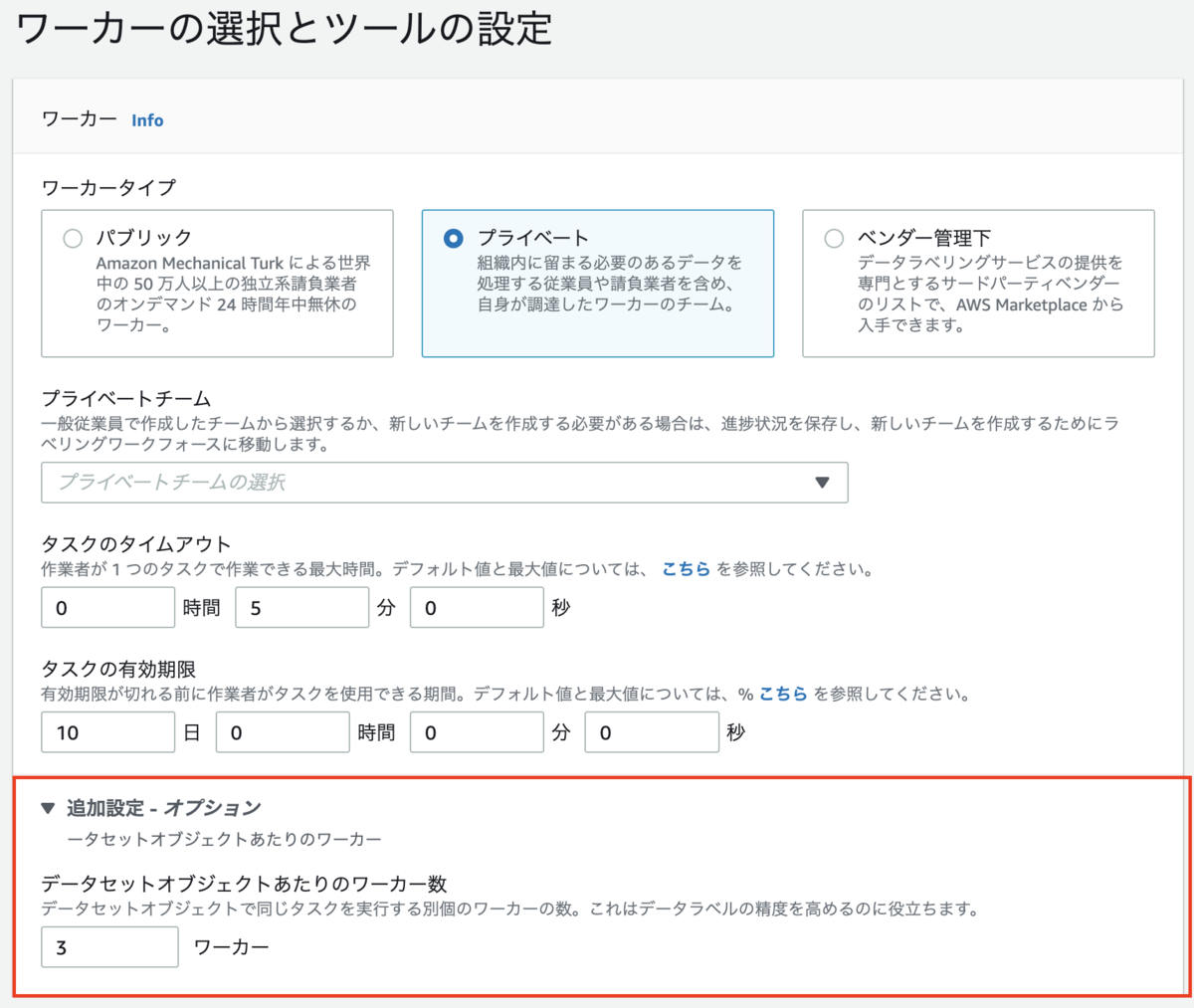
ちなみにGround Truthのジョブ作成時、ワーカー数の設定部分がデフォルトで折り畳まれていますが、この部分はタスクの難易度や必要な精度などを考えて調整しておくことを推奨します。(この部分の初期値が3になっており、そのまま変更し忘れていた場合にデータセットのサイズの約3倍のコストと作業時間がかかってしまった、といったトラブルが起きる可能性があります。)
アノテーション対象のフィルタリング
単にランダムサンプリングを行なったデータをアノテーションすると、BASEの商品全体において多数を占めるファッションカテゴリの商品にアノテーションが集中することになります。
一方でファッション商品は比較的分類が簡単なカテゴリのためそこまでサンプルサイズは必要なく、逆に分類が難しい少数派のカテゴリのサンプルサイズを確保しようとすると大量のデータをアノテーションしなくてはならなくなり、コストパフォーマンスが悪くなります。
そのため十分なサンプルが確保できたカテゴリから順次分類モデルを作成していき、モデルのテスト性能が十分だった場合はそのモデルを利用し、以降のアノテーションで事前にそのカテゴリと予測された商品を除外する処理を入れました。
こうして得られた学習データのカテゴリ分布は実際のカテゴリの事前分布と大きく異なることになるため、学習時のミニバッチの作成部分でサンプルサイズの調整を行いました。
モデルの学習とテスト
BERTのファインチューニング
分類モデルには事前学習済みのBERTをファインチューニングしたものを使用することにしました。
BERTをはじめとしたニューラルネットベースのモデルの利点としては
- テキストの文脈や単語の前後関係などを考慮できる点
- 凝った前処理が不要である点
- kaggleなどのコンペで多用されており、分類タスクにおける性能の高さが担保されている点
- 使いやすいライブラリ(主にHugging FaceのTransformers)が存在し、ベースモデルやタスクの変更、モデルの改造なども柔軟に行える点
- 使いやすい日本語の事前学習済みモデルが存在する点
などが挙げられます。
また、今回は導入していませんが、いずれテキストだけでなく商品画像も利用したマルチモーダルなモデルにすることも視野に入れています。*3
ラベルのついたデータセットをtrain/evalに分け*4、商品のタイトルおよび説明文を結合したテキストデータを簡単に前処理し、PytorchのDataset化した後でtransformersのTrainerクラスにベースモデルと各種パラメータとともに渡します。
学習は社内のオンプレGPUマシン(RTX3090)を使用しました。
ファインチューニング部分の実装例
import pandas as pd from transformers import TrainingArguments, Trainer, AutoModelForSequenceClassification, AutoTokenizer, EarlyStoppingCallback, ProgressCallback class BertClassifier: def __init__(self, target_label: str, model: str, tokenizer: str, num_labels: int): self.model = AutoModelForSequenceClassification.from_pretrained(model, num_labels=num_labels) self.tokenizer = AutoTokenizer.from_pretrained(tokenizer) self.item_category_collator = ItemCategoryCollator(self.tokenizer) self.model.config.id2label = {0: f"not_{target_label}", 1: target_label} def fit(self, df_train: pd.DataFrame, df_eval: pd.DataFrame, early_stopping_patience: int, training_args: TrainingArguments) -> None: dataset_train = ItemCategoryDataset(df_train) dataset_eval = ItemCategoryDataset(df_eval) trainer = Trainer( model=self.model, args=training_args, compute_metrics=self.metrics, train_dataset=dataset_train, eval_dataset=dataset_eval, tokenizer=self.tokenizer, data_collator=self.item_category_collator, callbacks=[ EarlyStoppingCallback(early_stopping_patience=early_stopping_patience), ProgressCallback()], ) trainer.train(ignore_keys_for_eval=['last_hidden_state', 'hidden_states', 'attentions']) def evaluate(self, df_test, batch_size): ... def inference(self, df_inference, batch_size): ...
モデルの性能評価
作成したモデルの性能を検証するためのテストデータは学習データセットと同時期の商品群および比較的最近の商品群からのランダムサンプルの2種類を用意しました。*5 複数の正解ラベルがついた1つの商品に対して8つの2値分類モデルで推論を行い、モデルの出力が閾値0.5を上回ったラベルと正解ラベルを比較する形で性能評価を行いました。
商品カテゴリの分類はマルチクラス・マルチラベルの分類タスクであり、ラベルは不均衡であるものの誤分類コストについては不正検知のようにそこまで非対称性があるわけではないという点を踏まえ、性能評価の指標としてはミクロ/マクロのf1スコアを重視しつつ、ミクロ/マクロの適合率(precision)、再現率(recall)やラベルごとの適合率、再現率なども参照しました*6。
テスト結果の例
| scores | precision | recall | f1-score |
|---|---|---|---|
| micro_avg | 0.882 | 0.885 | 0.884 |
| macro_avg | 0.746 | 0.742 | 0.732 |
| weighted_avg | 0.884 | 0.885 | 0.882 |
数値に対応するイメージ
● 全体的に漏れなく検出されている(どの商品を見てもきちんとラベルが付いている)
● 全体的に誤分類が少ない(デタラメなラベルが少ない)
● 極端に検出漏れがあるクラスがない(特にラベルが付きにくいカテゴリが少ない)
● 極端に誤分類が多いクラスがない(特にデタラメなラベルがついているカテゴリが少ない)
全体の多くを占めるファッション系のスコアが高いためミクロf1スコアは高い一方、一部分類が難しい少数派のカテゴリのスコアが低くなったため、マクロf1スコアは比較的低い値となっています。ミクロf1スコアをキープしたまま分類が難しいカテゴリのモデルを改良し、マクロf1スコアを改善していくことが今後の課題となります。
gokartを利用したパイプラインの構築
今回は2値分類モデルを複数組み合わせることでマルチラベル分類モデルを作成しているため、全体として以下のように若干煩雑なワークフローとなっています。(実際には画像ベースのモデルの検証など間に色々と実験を挟んでいるのでよりカオスです。)
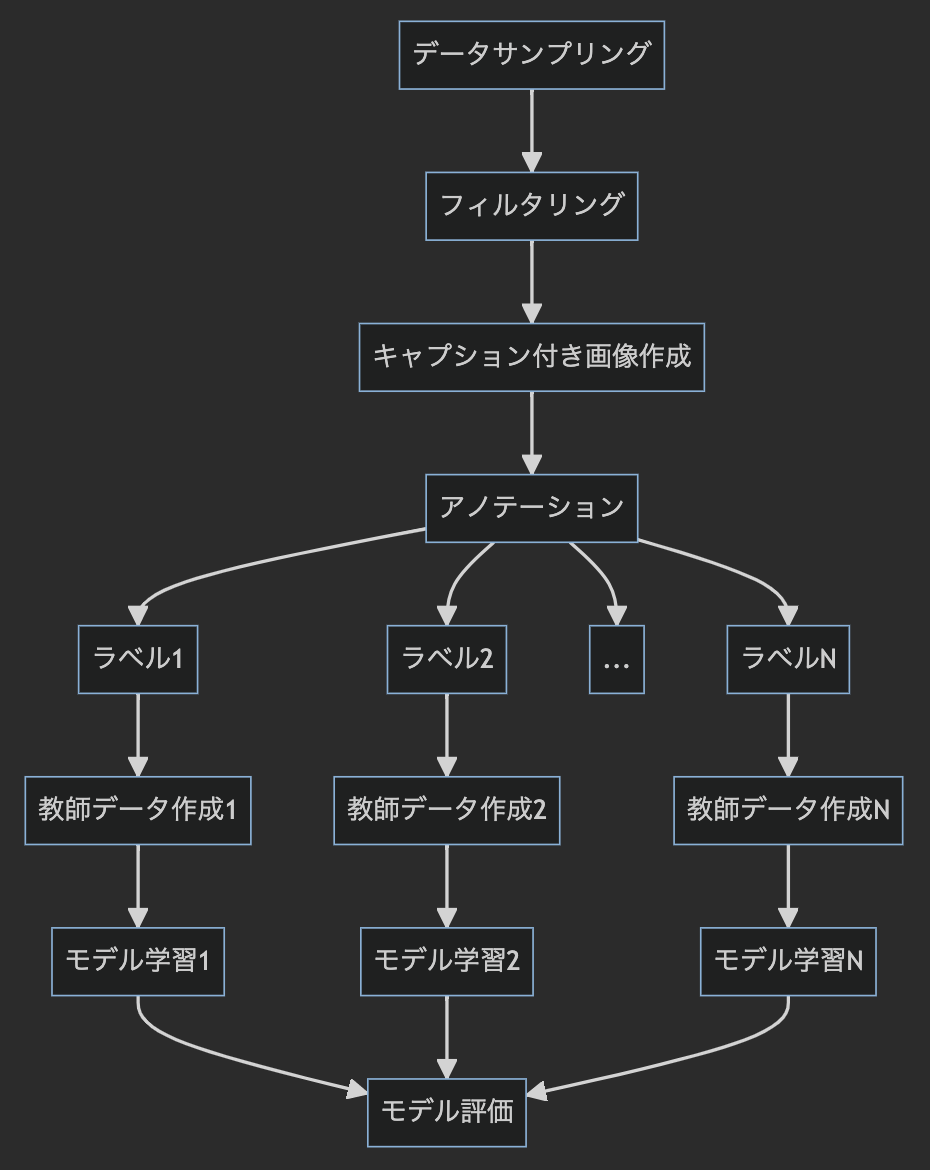
こうしたワークフローをうまく整理し、他のメンバーが手元で作業を再現しやすくする目的で、画像などの生データのバージョン管理にData Version Controlを利用し、ワークフローの実装にはエムスリーさんが開発されているオープンソースのパイプラインツールであるGokartを利用させていただきました。
gokartはS3との連携も容易なため、学習したモデルのチェックポイントをそのまま推論基盤から利用することでモデルのデプロイやバージョン管理もスムーズに行うことができました。
AWS Batchを利用したバッチ推論基盤
DataStrategyチームではバッチ処理は基本的にFargateを使用していますが、今回は処理にGPUインスタンスが必要となり、残念ながらFargateはまだGPUに対応していないため、今回はAWS Batch+EC2のGPUインスタンス(g4dn)を利用しました。
常時推論対象となる商品をSQSに保存していき、1日に1回AWS BatchからGPUインスタンスを複数台起動しバッチ処理を行なっています。
推論部分に関してはtransformersのTextClassificationPipelineを使用するとかなりすっきりと実装することができます。
推論部分の実装例
import pandas as pd from torch.utils.data import Dataset from transformers import TextClassificationPipeline from transformers.modeling_utils import PreTrainedModel from transformers.pipelines.pt_utils import KeyDataset from transformers.tokenization_utils import PreTrainedTokenizer def inference( df_inference_target: pd.DataFrame, model: PreTrainedModel, tokenizer: PreTrainedTokenizer, target_label: str, batch_size: int = 16, device: int = 0, ) -> pd.Series: result = [] classifier = TextClassificationPipeline( model=model, tokenizer=tokenizer, framework="pt", task="item_category", batch_size=batch_size, device=device, num_workers=2 ) dataset = ItemCategoryDataset(df_inference_target) tokenizer_kwargs = { "padding": True, "truncation": True, "max_length": tokenizer.model_max_length, } for out in classifier( KeyDataset(dataset, "text"), batch_size=batch_size, **tokenizer_kwargs ): if out["label"] == target_label: score = out["score"] else: score = 1.0 - out["score"] result.append(score) return pd.Series(result)
推論された結果は社内のデータウェアハウスに保存され、他のデータと合わせた分析や、Lookerを使用したダッシュボード化などに利用することができます。
おわりに
今回は機械学習モデルを利用した商品カテゴリの推論基盤に関する取り組みについてご紹介させていただきました。
今後に向けて
- より詳細なカテゴリの分類
- データセットの拡大(精度の向上)
- 商品画像の利用(マルチモーダル化)
- モデルの精度監視と継続的アップデート
- Out of Distributionの検知
などなど色々と課題は残っていますが、ひとまず今まで把握できていなかった商品単位の粒度まで解像度を上げた分析が可能となり、既存の別の機械学習モデルの特徴量として使用したり、検索や推薦の精度を上げたり、カテゴリが設定されていないショップのジャンルを推論したりと色々な用途で活用が見込めそうです。
さて、DataStrategyチームでは機械学習エンジニアとして一緒に働いてくださる方を積極採用中です。カジュアル面談も実施しているのでぜひお気軽にご連絡ください。
明日は @yuzuy @ayako-hotehama の記事が公開予定です、ぜひご覧ください。
*1:こちらの記事を参考にさせていただきました。 https://qiita.com/mo256man/items/b6e17b5a66d1ea13b5e3
*2:セット商品やスポーツウェアなど、複数のカテゴリにまたがって属する商品も存在するためマルチラベルとしました。
*3:timmのモデルの出力を正規化してconcatするなどナイーブな手法は色々試したものの、BERT単体のモデルを上回らない結果となりました。悲しい。
*4:同じショップがtrain/evalに分かれないようショップのIDでGroupFoldしています。性能検証で使用したテストデータにも学習時に使用したショップが含まれないようにしています。
*5:登録時期によるデータドリフトの影響も見たかったため。実際はそこまで影響はなかったので最終的に1つのテストデータにまとめてしまいました。
*6:各種スコアの定義はsklearnのdocmentが参考になります。