
この記事はBASE Advent Calendar 2020の11日目の記事です。
BASE株式会社 Data Strategy チームの@tawamuraです。
BASEではオーナーの皆様や購入者様のお問い合わせに対して、Customer Supportチームが主となって対応をしています。その中でもいくつかの技術的なお問い合わせに対しては、以下のようにSlackの専用チャンネルを通して開発エンジニアに質問を投げて回答を作成することになっています。
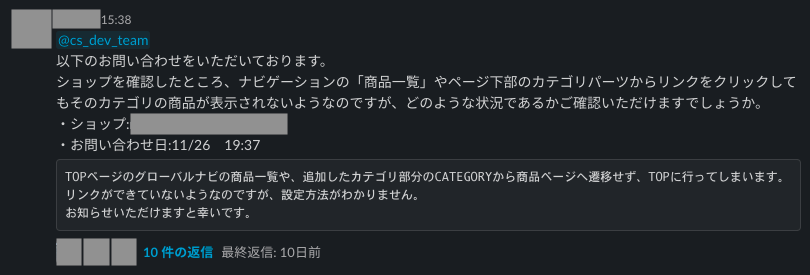
これらのCS問い合わせ対応は日々いくつも発生しており、CSお問い合わせ対応を当番制にして運用してみた話 でもあるように週ごとに持ち回り制で各部門のエンジニアが対応しているのですが、どうしても調査や対応に時間が取られてしまうという問題が発生していました。
ただ、いくつかの新規問い合わせに関しては過去に同様・類似のお問い合わせ事例があり、調査や回答の参考になる場合もありました。それならば、過去の類似の投稿を自動で取ってきてBotが提示することで、問い合わせ対応の一助となるかと思いました。
Botの提示例(社内情報が多く、マスクばかりで恐縮です)
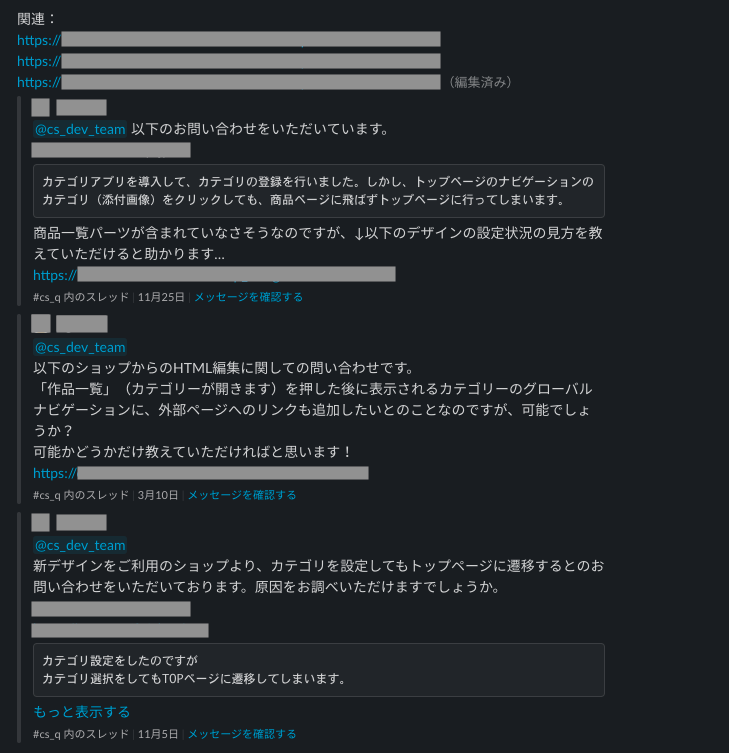
今回は、その問い合わせ対応半自動化のシステム構築についてお話しさせていただきます。ちなみに、この内容は Data Strategy チームの HackWeek の導入とその効果 で行なった1週間の実施タスクでして、今回はここでの結果にもう少し機能追加などを行い整えた記事になります。
技術選定、システム概観
弊社はAWSで環境構築を行なっている部分が多いため、今回もAWS環境を前提に進めます。
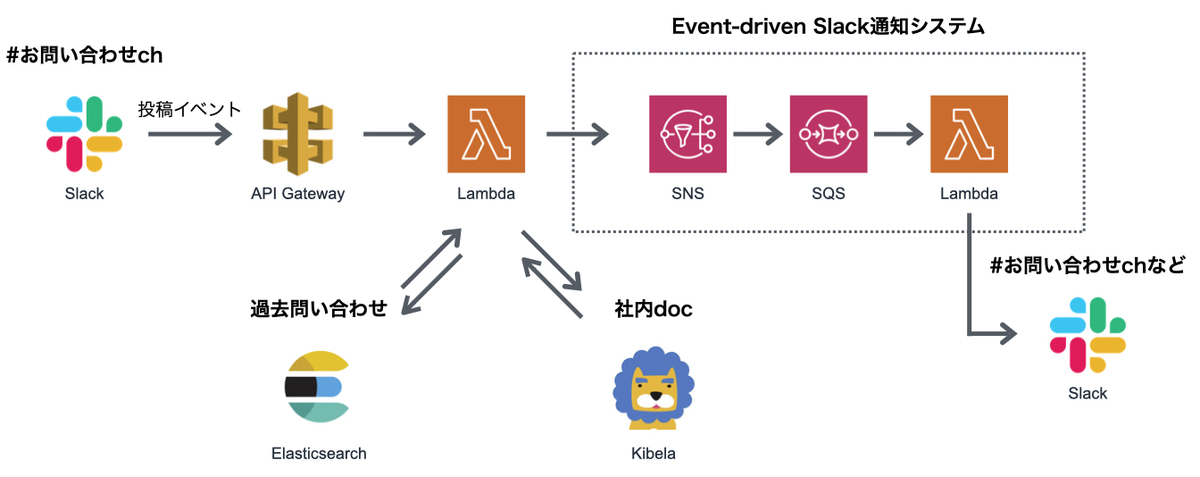
結果的に以下のようなシステムを構築しました。
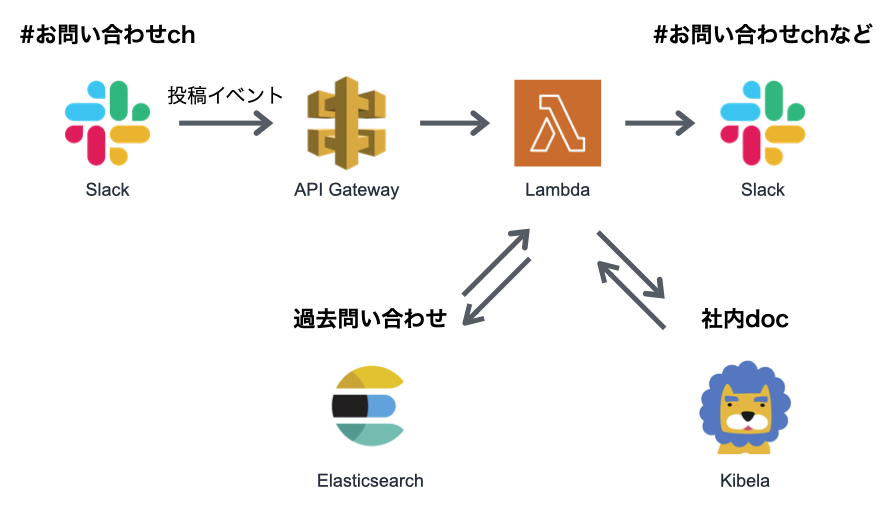
まず、特定チャンネルにおいてSlackに新規問い合わせがあった時にそれをイベントとして拾います。そこで拾ったイベントをAWS上で活用しやすいようにAPI Gatewayを使用します。
API Gatewayでイベントを受け取った後に、実際にその内容に対して処理を行うのですが、問い合わせは多いと言ってもデイリーで数十件には上らない程度の発生頻度であり、あまり重い処理を行うわけではないことから、AWS Lambdaを使用することにしました。
Lambda内ではお問い合わせ内容について類似する過去の問い合わせの検出と、弊社でドキュメントサービスとして使用しているKibelaの記事のうち関連する記事を取得する処理を行います。過去の問い合わせ検出には、大量のSlackドキュメントから全文検索により取得することを考えてElasticsearchを使用しました。
受け取った情報からレスポンスを整形し、Slackの特定のチャンネルに投稿します。今回はあくまでサブ機能としての提供で考えていたので、別途自動回答チャンネルを設けてそちらに書き込みをさせました。
弊社の場合、Slackに投稿する部分については、SNSに特定のイベントを投げることで完結するようなシステムがすでにありますので、具体的には以下のようなフローになっています。こちらのSlack投稿システムについては本記事では割愛し、直接Slackに投稿できるようなものを紹介します。
Slack、API Gatewayなどの連携設定
Slackの投稿内容をLambdaで解析するためには、Slackの投稿イベントを拾いAPI Gatewayを通してAWS内で扱えるようにし、Lambdaに紐つけることでイベント内容を処理するという一連の連携の設定が必要になります。
こちらの内容については、以下の記事で同様の連携設定がまとめてありますので、そちらを参考に構築していただければと思います。図解も詳しくとてもわかりやすいです。
上記連携を行うことで、Botを追加したチャンネルでの新規投稿について、Lambdaでの個別処理を行うことができます。 今回はPythonでの処理を想定しているので、Lambda作成時のランタイムですが、記事にあるようにPython 3.6やPython 3.7などに指定してください。
過去のSlack投稿の取得と解析、Elasticsearchへの保存
Slack投稿の取得
作成したBotのtokenを利用して、まずは過去のSlackの問い合わせ投稿の取得を行います。Jupyter Notebookなどで実施するのをお勧めします。
headers = {
"Content-type": "application/json",
"Authorization": f"Bearer {token}" # 取得したslack botのtoken
}
# 決めで2018年以降の投稿を取得
def fetch_messages_by_channel(channel_id):
oldest_ts = None
start_date = pd.to_datetime('2018-01-01')
endpoint = 'https://slack.com/api/conversations.history'
ls_messages = []
while True:
payload = {
'channel': channel_id,
'latest': oldest_ts,
'count': 1000
}
data = requests.get(endpoint, headers=headers, params=payload).json()
messages = data['messages']
ls_messages.extend(messages)
if data['has_more']:
time.sleep(1)
oldest_ts = messages[-1]['ts']
oldest_datetime = pd.to_datetime(oldest_ts, unit='s')
sys.stdout.write(f"\r{oldest_datetime}")
sys.stdout.flush()
if oldest_datetime < start_date:
sys.stdout.write(f"\rfinish!" + ' '*50)
break
else:
break
df = pd.DataFrame(ls_messages)
df['channel_id'] = channel_id
return df
対象となるチャンネルのIDは以下のエンドポイントから取得可能(チャンネル数が1000を超える場合は、適宜ループ取得をしてください)。以下は対象チャンネルが#お問い合わせチャンネルの場合の例です。
endpoint = 'https://slack.com/api/conversations.list' payload = {"limit": 1000} data = requests.get(endpoint, headers=headers, params=payload).json() channel_df = pd.DataFrame(data['channels']) display(channel_df.query("name == 'お問い合わせチャンネル'"))
取得したいチャンネルのIDがわかったら、先ほどの関数に渡すことで再帰的に過去の投稿を取得できます。
messages_df = fetch_messages_by_channel(channel_id)
2018年以降の投稿を取得するのですが、1000件ずつ取得していって2018年以前になっていたら終了するというループなので、厳密には2017年後半に一部も含まれます。
続いて、取得したデータを整形していきます。同時に該当の投稿へリダイレクトできるリンクを取得情報から作成します。
# typeの選別 not_message_types = ['channel_join', 'channel_leave', 'channel_topic', 'channel_archive', 'channel_purpose', 'sh_room_created', 'channel_name', 'pinned_item', 'reminder_add', 'app_conversation_join'] messages = messages[~messages['subtype'].isin(not_message_types)] # slack linkの作成(ドメイン名は適宜変更してください) messages["link"] = "https://xxx.slack.com/archives/" + messages["channel_id"] + "/p" + messages["ts"].str.replace('.', '')
次に問い合わせ投稿の抽出を行います。弊社の場合、@cs_dev_teamというメンショングループで投稿されているものがそれに該当するため、それらの投稿を抽出します。
# subteamのIDはmessages_dfの中身を確認するなどして代入してください cs_res_df = messages[messages["text"].str.contains("<!subteam^*********|@cs_dev_team>")]
これで期間中の全投稿messages_dfと問い合わせ投稿のcs_res_dfが作られたことになります。
問い合わせ文書の解析
問い合わせ投稿の類似投稿の検索や、社内ドキュメントの検索のために、新規問い合わせの文章を適切に処理して行えるよう事前に解析しておきます。
import re import mojimoji # 事前に不要な項目をtextから削除する関数 def filter_contents(text): # タグ・emojiは削除 subed = re.sub("<.*?>", "", text) subed = re.sub(":.*?:", "", subed) # その他、社内独自ID系などの削除処理 # ******** return subed # 単語の正規化 def normalize(text): text = text.strip() text = mojimoji.zen_to_han(text, kana=False) text = mojimoji.han_to_zen(text, digit=False, ascii=False) text = text.lower() return text
全投稿文から名詞のみ抽出します。形態素解析器はJanomeを使用しました。あとでも触れますが、Janomeは辞書も含めてpipで簡単にインストールすることができるので、Lambdaのような環境で簡単に形態素解析を行うのに適しています。
from janome.tokenizer import Tokenizer t = Tokenizer() ndocs = [] for line in tqdm(messages_df["text"]): parsed = [] subed = normalize(filter_contents(line)) # janomeは改行を無視できない for token in t.tokenize(" ".join(subed.split("\n"))): tok = token.surface hinsi, sub, _ = token.part_of_speech.split(",", 2) # 数字のみは名詞だがスキップ if tok.isdecimal(): continue if hinsi == "名詞": parsed.append(tok) ndocs.append(" ".join(parsed))
これでndocsに名詞列のスペース区切り文字列が投稿数分だけlistとして格納されます。
これを利用してチャンネル全体での単語のTFIDF値(重要度のようなもの)を計算します。TDIDFについては以下の記事などをご参照ください。今回は簡単のためにscikit-learnに含まれるTfidfVectorizerを計算に使用しました。
from sklearn.feature_extraction.text import TfidfVectorizer # 文書全体の90%以上で出現する単語は無視、語彙数は10000のみ vectorizer = TfidfVectorizer(max_df=0.9, max_features=10000) X = vectorizer.fit_transform(ndocs) words = noun_vectorizer.get_feature_names() idf_list = ["\t".join(map(str, line)) for line in list(zip(vectorizer.get_feature_names(), vectorizer.idf_))] pd.DataFrame(idf_list).to_csv("./idf.tsv", index=False, header=False)
これでidf.tsvというIDF辞書が作成できます。
単品 9.973116006811027 匿名 9.839584614186505 カーソル 9.21097595476413 ショップ 3.3278392845417772 :
TF値は新規問い合わせ時にわかりますので、これで新規問い合わせについての名詞のTFIDF値が計算できることになります。
Elasticsearchに過去問い合わせを保存
過去の問い合わせをElasticsearchに保存して、新規問い合わせが来た時に検索をかけられるようにします。まずElasticsearchに過去問い合わせ用のインデックスを作成します。事前にboto3で使用するcredentialsを以下の記事など参考に取得できるよう設定しておく必要があります。
import io import boto3 from requests_aws4auth import AWS4Auth from elasticsearch import Elasticsearch, RequestsHttpConnection region = 'ap-northeast-1' service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service, session_token=credentials.token) es = Elasticsearch( hosts = [{'host': '{Elasticsearchのhost}', 'port': 443}], http_auth = awsauth, use_ssl = True, verify_certs = True, connection_class = RequestsHttpConnection ) index_name = "autores_index" mappings = { 'properties': { 'orig_text': { 'type': 'text' }, 'text': { 'type': 'text', 'analyzer': 'autores_kuromoji_analyzer' }, 'keyword': { 'type': 'text', 'analyzer': 'autores_kuromoji_analyzer' }, 'ts': { 'type': 'text' }, 'thread_ts': { 'type': 'text' }, 'link': { 'type': 'text' }, } } settings = { 'analysis': { 'analyzer': { 'autores_kuromoji_analyzer': { 'type': 'custom', 'tokenizer': 'kuromoji_tokenizer' } }, 'autores_kuromoji_tokenizer': { 'kuromoji': { 'type': 'kuromoji_tokenizer' } } } } es.indices.create(index=index_name, body={'settings': settings, 'mappings': mappings})
登録するtextなどについて、analyzerにkuromoji_tokenizerを使用することで、全文検索時に形態素解析を活用した検索をすることができます。
過去の問い合わせ投稿について、Elasticsearch用の事前処理を行います。
bulk_dataset = [] for index, row in tqdm(cs_res_df.iterrows(), total=cs_res_df.shape[0]): text = row["text"] ts = row["ts"] thread_ts = row["thread_ts"] link = row["link"] # タグ除去(メンションやリンク) subed_text = filter_contents(text) # tokenize keyword = " ".join(tp.make_tokens(subed_text)) tfidf_score, unique_keys, shop_ids, phrase_list = tp.process(text) # skip too short message if len(subed_text) < 30: continue # bulk bulk_dataset.append({"index": {"_index": index_name}}) bulk_dataset.append({ "orig_text": text, "text": subed_text, "keyword": keyword, "ts": ts, "thread_ts": thread_ts, "link": link, })
def bulk(data, dry=False): if len(data) == 0: return buf = io.StringIO() for d in data: buf.write(json.dumps(d, ensure_ascii=False)) buf.write("\n") buf.seek(0) if dry: print(buf.read()) else: body = buf.read() es.bulk(body)
以下で200件ずつデータをinsertしていきます。
rest_dataset= bulk_dataset insert_rows_len = 200 while len(rest_dataset) > 0: data = rest_dataset[:insert_rows_len] bulk(data) rest_dataset = rest_dataset[insert_rows_len:]
これでElasticsearchのautores_indexにデータが追加されます。以下のクエリなどでデータを確認できます。
es.search(
scroll='5m',
index=index_name,
body={
"query": {
"match_all": {
}
},
"_source": [
"orig_text",
"link"
],
},
)
処理Lambdaの実装
Lambdaで実装するのは主に以下の処理です。
- API Gatewayから流れてきたイベントを正しく受け取って処理可能な状態にする
- テキスト解析を行いElasticsearch、Kibelaの検索を行う
- BotとしてSlackへ回答を投稿する
いくつかLambdaで新しく導入する必要のあるモジュールがありますが、それはLambda Layerという形で事前に基盤のようなものを用意しておくことになります。
requirements.txtに追加で必要なモジュールを記載し、それらのファイルを一つのzipとしてまとめる必要があります。同時に、事前に作成したIDF辞書もここでLayer内に含めます。以下のようなMakefileを同階層に作って構築すると楽です。
janome requests_aws4auth elasticsearch mojimoji
build-layer: rm -rf python && mkdir -p python docker run --rm -v ${PWD}:/var/task lambci/lambda:build-python3.7 \ pip install -r requirements.txt -t python cp idf.tsv python zip -r autores_layer.zip python rm -rf python
以下のコマンドで、Layerに適用可能なzipファイルautores_layer.zipが作成されます。これをLayerとして新規登録しましょう。Webでもできますし、CLIツールでも可能だと思います。
$ make build-layer
今回、Lambda上で形態素解析を行うためにJanomeを採用したと言いましたが、理由として動作が軽いのと、シンプルなpipによるインストールで完結していることが理由として挙げられます。他の形態素解析器でもLayerやEFSなどを活用することでLambda上でも使用できるようなのですが、手っ取り早く扱いづらかったため今回は見送りました。
LambdaのWeb管理画面に行き、新規関数を作成していきます。これは前に説明したAPI Gatewayとの連携設定をしていれば、そのLambda関数を選択するので問題ないです。 まずLayerとして先ほど新規作成したLayerを使用します。
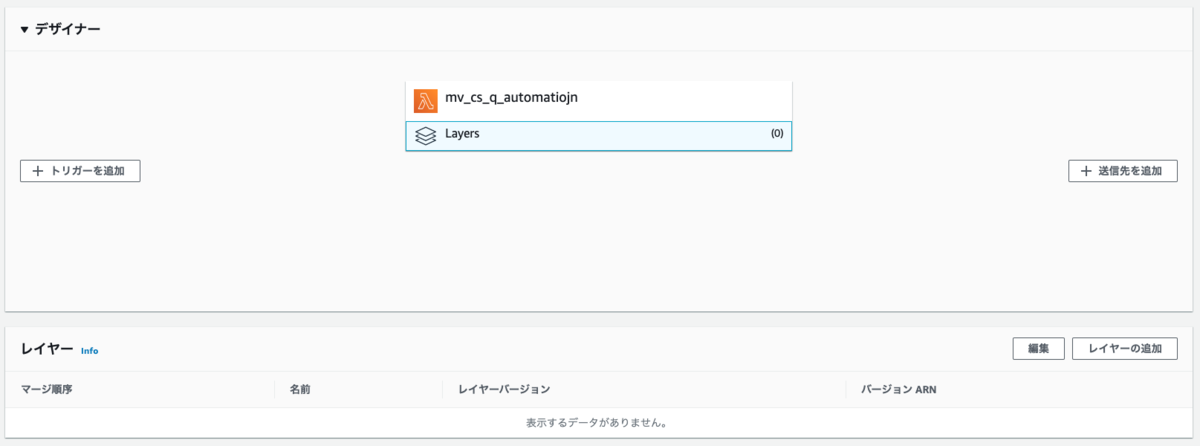
デザイナータブ内のLayersをクリックすると、下部にレイヤーを管理するタブが出ますので、そこでレイヤーの追加を行います。Layer追加時に互換性のあるランタイムでPython3.7などを指定していればカスタムレイヤーで選択できますが、直接LayerのARNを指定するのでも問題ありません(ARNはLayerの画面右上などにあります)。
Lambdaの設定ですが、使用メモリを512MBとしています。Janomeでの形態素解析を行うのに少し余裕が必要になるためですが、このくらい確保しておけば大抵は動作するかと思います。
次にfunction.pyの中身を実装します。
import boto3 from requests_aws4auth import AWS4Auth from elasticsearch import Elasticsearch, RequestsHttpConnection import json import logging import io import requests import urllib import mojimoji import re from janome.tokenizer import Tokenizer import collections import time import hmac import hashlib logger = logging.getLogger() logger.setLevel(logging.INFO) KIBELA_DOMAIN = "****.kibe.la" # Kibelaのドメイン KIBELA_KEY = "secret/***************" # KibelaのAPIキー ES_DOMAIN = "********.es.amazonaws.com" # Elasticsearchのドメイン SLACK_DOMAIN = "******.slack.com" # Slackのドメイン SLACK_SIGNING_SECRET = "************" # SlackのSigning Secret BOT_TOKEN = "xoxb-********************" # Slack Botのtoken BOT_USER_ID = "U*********" # Slack Botのuser_id INDEX_NAME = "autores_index" # elasticsearchのインデックス名 REGION = "us-east-1" # 利用中のregion OUT_CHANNEL = "#autores_bot" # Botの投稿先チャンネル service = 'es' credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, REGION, service, session_token=credentials.token) es = Elasticsearch( hosts=[{'host': ES_DOMAIN, 'port': 443}], http_auth=awsauth, use_ssl=True, verify_certs=True, connection_class=RequestsHttpConnection ) def is_valid(event): if SLACK_SIGNING_SECRET is None: return False if "x-slack-signature" not in event["headers"] or "x-slack-request-timestamp" not in event["headers"]: return False timestamp = int(event["headers"]["x-slack-request-timestamp"]) if abs(time.time() - timestamp) > 60 * 5: return False request_body = event["body"] sig_basestring = f"v0:{timestamp}:{request_body}" digest = hmac.new( SLACK_SIGNING_SECRET.encode(), sig_basestring.encode("utf-8"), hashlib.sha256).hexdigest() my_sig = f"v0={digest}" if hmac.compare_digest(my_sig, event["headers"]["x-slack-signature"]): return True else: return False def event_to_json(event): # API Gatewayから流れてきたイベントから本文を抽出 if 'body' in event: body = json.loads(event.get('body')) return body elif 'token' in event: body = event return body else: logger.error('unexpected event format') exit class TfidfProcessor(): def __init__(self): self.word2idf = {} self.subed = "" self.tokens = [] self.tfidf_score = {} self.phrase_list = [] # Layer内のIDF辞書を読み込み with open("/opt/python/idf.tsv") as f: for line in f: word, score = line.rstrip().split("\t") self.word2idf[word] = score self.t = Tokenizer() def process(self, text): self.filter_contents(text) self.make_tokens() self.calc_tfidf() self.extract_phrase() return self.phrase_list def normalize(self, text): text = text.strip() text = mojimoji.zen_to_han(text, kana=False) text = mojimoji.han_to_zen(text, digit=False, ascii=False) text = text.lower() return text def filter_contents(self, text): # タグ・emojiは削除 subed = re.sub("<.*?>", "", text) subed = re.sub(":.*?:", "", subed) # その他、社内独自ID系などの削除処理 # ******** self.subed = self.normalize(subed) def make_tokens(self): self.tokens = list(self.t.tokenize(" ".join(self.subed.split("\n")), wakati=True)) def calc_tfidf(self): tf_dic = self.calc_tf() idf_dic = self.calc_idf() for token, idf_score in idf_dic.items(): self.tfidf_score[token] = float(tf_dic[token]) * float(idf_score) def calc_tf(self): tf_tokens = {} tokens_len = len(self.tokens) counts = collections.Counter(self.tokens) for token, freq in counts.items(): tf_tokens[token] = freq / tokens_len return tf_tokens def calc_idf(self): idf_tokens = {} for token in self.tokens: if token in self.word2idf: idf_tokens[token] = self.word2idf[token] return idf_tokens def extract_phrase(self): phrase = {} tmp_phrase = [] for token in self.t.tokenize(" ".join(self.subed.split("\n"))): tok = token.surface hinsi, sub, _ = token.part_of_speech.split(",", 2) # ストップワードなどあれば、この辺りで処理しておく self.tokens.append(tok) if tok in self.tfidf_score and hinsi == "名詞": tmp_phrase.append(tok) elif len(tmp_phrase) > 0: phrase["".join(tmp_phrase)] = sum( [self.tfidf_score[tp] for tp in tmp_phrase] ) tmp_phrase = [] phrase_score_list = sorted(phrase.items(), key=lambda x: x[1], reverse=True) self.phrase_list = [phrase[0] for phrase in phrase_score_list] # for link with slack event subscriptions class ChallangeJson(object): def data(self, key): return { 'isBase64Encoded': 'false', 'statusCode': 200, 'headers': {}, 'body': key } def search_es(phrase_list): res = es.search( scroll='5m', index=INDEX_NAME, body={ "query": { "match": { "text": " ".join(phrase_list[:20]), } }, "_source": [ "text", "ts", "link", ], "size": 3, }, ) return res def search_kibela(phrase_list): # 互いに含有しないtfidf値の高い最大2単語をクエリとして使用 q = phrase_list[0] for p in phrase_list[1:]: if p in q: continue q = q + " " + p break # 全検索(合計で最大3件になるまで) res_text_list = [] query = """ query { search(query: \"""" + q + """\", first: 10) { edges { node { title, url, folder { fullName } } } } } """ res = get_kibela(query) for edge in res["data"]["search"]["edges"]: title = edge["node"]["title"] url = edge["node"]["url"] # 適宜取りたくない記事はルールベースでスキップ if re.search(r'hoge|fuga', title, re.IGNORECASE): continue res_text_list.append(f"{title}\n{url}") if len(res_text_list) > 2: break return "\n\n".join(res_text_list) def get_kibela(query): endpoint = f"https://{KIBELA_DOMAIN}/api/v1" headers = { "Authorization": f"Bearer {KIBELA_KEY}", "Content-Type": "application/json", "Accept": "application/json", } payloads = { "query": query } r = requests.post(endpoint, data=json.dumps(payloads), headers=headers) res = r.json() return res def save_to_es(text, tp, ts, thread_ts, target_link): bulk_dataset = [] bulk_dataset.append({"index": {"_index": INDEX_NAME}}) subed_text = tp.subed phrase_list = tp.phrase_list bulk_dataset.append({ "orig_text": text, "text": subed_text, "keyword": phrase_list, "ts": ts, "thread_ts": thread_ts, "link": target_link, }) bulk(bulk_dataset) def bulk(data, dry=False): if len(data) == 0: return buf = io.StringIO() for d in data: buf.write(json.dumps(d, ensure_ascii=False)) buf.write("\n") buf.seek(0) if dry: print(buf.read()) else: body = buf.read() es.bulk(body) def send_slack(channel, text): headers = { 'Content-Type': 'application/json; charset=UTF-8', 'Authorization': 'Bearer {0}'.format(BOT_TOKEN) } post_data = { 'channel': channel, 'text': text, } url = 'https://slack.com/api/chat.postMessage' req = urllib.request.Request( url, data=json.dumps(post_data).encode('utf-8'), method='POST', headers=headers ) urllib.request.urlopen(req) time.sleep(3) def lambda_handler(event, context): # verify slack if not is_valid(event): return body = event_to_json(event) # return if it was challange-event if 'challenge' in body: challenge_key = body.get('challenge') logging.info('return challenge key %s:', challenge_key) return ChallangeJson().data(challenge_key) # skip timeout retry, http_error retry if "x-slack-retry-reason" in event["headers"] and event["headers"]["x-slack-retry-reason"] in ("http_timeout", "http_error"): return # SlackMessageに特定のキーワードが入っていたときの処理 if "type" in body.get("event") and body.get("event").get("type") == "message" \ and "user" in body.get("event") and body.get("event").get("user") != BOT_USER_ID: text = body.get("event").get("text") # @cs_dev_teamのみ拾う if "<!subteam^*********|@cs_dev_team>" not in text: return channel = body.get("event").get("channel") ts = body.get("event").get("ts") thread_ts = body.get("event").get("thread_ts") target_link = "https://{}/archives/{}/p{}".format(SLACK_DOMAIN, channel, ts.replace('.', '')) # tokenizer tp = TfidfProcessor() phrase_list = tp.process(text) # search es es_res = search_es(phrase_list) es_list = [] for hit in es_res["hits"]["hits"]: link = hit["_source"]["link"] es_list.append(link) if len(es_list) > 2: break es_list_text = "関連:\n" + "\n".join(es_list) # search kibela kibela_res = search_kibela(phrase_list) # post message to main send_slack(OUT_CHANNEL, target_link) # post ref data message to main send_slack(OUT_CHANNEL, es_list_text) # post kibela message to main send_slack(OUT_CHANNEL, kibela_res) # save message for future questions save_to_es(text, tp, ts, thread_ts, target_link) return
コード中の各種キーやドメイン名などは、動作環境に合わせて適宜修正してください。
大枠の流れは、
- API Gatewayから受け取ったイベントを処理し、処理すべきイベントか判断
- Janomeを使用して本文を解析し、Elasticsearch、Kibelaを検索するための単語を抽出
- それぞれ検索を行い、結果をSlackに投稿
- 受け取った新規問い合わせは、次回の過去問い合わせとなるのでElasticsearchに過去問い合わせとして登録
という流れで処理を行います。
以下に一部コードを抜粋して説明します。
Slack周り
API Gatewayからイベントを受け取るときに、Slackからきたイベントだというのを判別するためis_validという関数で処理しています。下記リンクが詳細になります。SLACK_SIGNING_SECRETにはSlack Botの管理画面の「Signing Secret」を代入してください。
また、Botを使った自動投稿システムを作るときに、自分自身の投稿も反応対象として拾ってしまうと無限に投稿をし続けてしまうという問題が発生してしまいます。今回は特定のメンションを含むときを対象に抽出するので問題はないかもしれませんが、レスポンス内容を変更する場合は事前にBotからの投稿は無視するという処理をしておくと良いでしょう。
if "type" in body.get("event") and body.get("event").get("type") == "message" \ and "user" in body.get("event") and body.get("event").get("user") != BOT_USER_ID: text = body.get("event").get("text")
ここの部分です。Botのuser_idはどこにあるかわかりにくいですが、こちらでBotのtokenを渡すことで取得できると思います。
その他、投稿する内容についてはsend_slack内のpost_dataに追記することで色々できるようです。また、投稿についてですがAPI Limitなどの余裕を持って3秒ほどsleepさせています。
検索クエリの抽出ロジック
問い合わせのテキストを解析し、検索に使用する単語を抽出するのはTfidfProcessorクラスで行います。
具体的な処理の内容としては、
- 絵文字やリンクなどを削除
- 形態素解析をし、名詞についてのみ形態素群を抽出し、それぞれのTFIDF値を計算
- 形態素解析時に連続する名詞は名詞句として扱い、TFIDF値は合算値とする
- 「振込/申請」とあった場合は、「振込申請」として「振込」と「申請」のTFIDF値を合算したものを使用する
- TDIFD値の高い順に名詞・名詞句を並び替えておく
という流れになります。これによりTFIDF値の高い名詞・名詞句が獲得できるようになったので、以下のようにそれぞれ検索を行っています。
- Elasticsearchでは上位20件の名詞・名詞句の空白区切りテキストを、過去問い合わせのtextに対して全文検索する
- (結構適当でもうまくやってくれるイメージです)
- Kibelaでは上位2件の名詞・名詞句をスペース区切りでクエリとして全文検索する
- 「振込申請」「振込」「注文」と続く場合は「振込申請」「注文」を選択するような処理を入れています
過去問い合わせとKibelaドキュメントのどちらも最大3件までとしました。
Kibela検索クエリについて
Kibela APIの検索クエリはGraphQLで書く必要があります。
以下のschemaに沿ってクエリを作成します。
特定のフォルダ直下で検索したいときなどは、
query {
search(query: "hoge fuga", first: 10), folderIds: ["{フォルダのID}"]) {
edges {
node {
title,
url,
folder {
fullName
}
}
}
}
}
という風に書くと絞り込みができたりしますので、弊社の場合はその検索も併用していたりします(フォルダIDはAPIを叩いて得られたものを手で入れました)。
デプロイ
あとは保存をしてデプロイを行うだけです。うまくいけば、特定チャンネルの対象グループへのメンション投稿に対して、
- そのメンションへのリンク(展開されます)
- Elasticsearchを利用した過去問い合わせ3件へのリンク(展開されます)
- Kibelaで検索した関連記事3件のタイトルとリンク
が指定したチャンネルに順次Botから投稿されるかと思います。イメージは冒頭の画像の通りです。
実際には綺麗な出力にしていくためには、ストップワードを人手で登録したり、Kibelaの検索を細かい設定で分けたりフィルターをかますことで結果の記事を良い感じに調整するような泥臭い作業が重要になってきます。本記事では具体例は割愛しましたが、その辺りはいくつかサンプルで試してみて見つけつつ、運用が始まったら実際の出力などをみつつさらに調整する感じが良いかと思います。
終わりに
エンジニアによる調査が必要だったりする技術的なお問い合わせに対して、過去の類似したお問い合わせや関連する社内ドキュメントの推薦を行うシステムを社内で導入した件についてまとめました。まだまだ精度改善の余地などはありますが、これ以前もあったような気がするな・・?というようなお問い合わせについては過去の事例を参照することで、同様の調査や回答の作成を楽に行えるようになったかと思います。実際に「自動で出してもらった回答がそのまま使えました!」というような声もいただいたりしました。
弊社の場合はSlack通知部分をSNSなどを利用して汎用システムとして用意していたり、各サービスの連携や変数などは構成管理ツールで管理させていたりします。また、実際には構築済みのVPC内で実装を行っていましたが、それらの説明については今回は省略しました。BASEでは現在、不正検知エンジニアを中心に機械学習エンジニアを募集しています。詳しいお話などは是非ご面談等でお話お伺いできればと思います!
今後も引き続き改善を行い、より早くお問い合わせの返信を行えるよう努力していければと思います。 明日はService Devチームの炭田さんです!お楽しみに!