
本記事はBASEアドベントカレンダー2024の14日目の記事です。
はじめに
BASE の Product Dev Division でエンジニアリングマネージャー(EM)をしている @tanden です。
Product Dev Division では、ここ 1 年ほどサービスレベルマネジメントの取り組みを有志メンバーを中心としたチームで進めてきました。この記事では、サービスレベルマネジメントの取り組みの一貫として行ったアラート品質改善についてまとめています。
SLI/SLO設定のその前に
サービスレベルマネジメント(SLM)というと SLI/SLO について最初に思い浮かぶ方も多いのではないでしょうか。ただ、SLI/SLO の設定にトライされたことがある方はご理解いただけると思いますが、組織として納得感を持ってかつ効果的な形で設定するのは非常に難しい作業になります。また一度設定して終わりではなく、設定した SLI/SLO を見直しながらサービスの信頼性を継続的に高めていく取り組みが求められるので、長期目線で継続できるような体制を作っていく必要があります。
一方で、長期戦となる SLM の取り組みを進めるうえで、短期的な成果を上げることも重要です。初期の成果はチームに勢いをもたらすだけでなく、周囲の信頼を得るきっかけにもなります。逆に成果の見えにくい状態が続くと、チームのモチベーションも低下してしまい、最終的には取り組みが形骸化するリスクもあります。
そこで、今回の SLM の取り組みでは、最初の成果として開発組織の困り事として挙がることが多かった「アラート品質の向上」に狙いを定めることにしました。アラート自体はサービスレベルマネジメントのコアとなるようなプラクティスではありません。ですが、例えば適切なアラート通知によってエラーバジェットの枯渇を未然に防ぐなど、SLO を達成するための重要なツールの 1 つとして位置づけられるはずです。
アラートの品質管理については、New Relic のドキュメントやブログでもアラートクオリティマネジメント(AQM)として紹介されています。ぜひ一度ご覧ください。
課題と取り組み
ヒアリングや自身の開発体験をもとに課題の整理をまずは行いました。その結果、アラートにおける課題を以下の 3 つに絞り込むことができました。
- どのアラート通知チャンネルを見るべきかわからない
- アラートが多すぎてどれが重要かわからない
- アラートが出たとしても何をしていいのかわからない
全ての課題に共通して言えるのは「アラートが発生しても、次のアクションに素早くつなげにくい」ということです。そこでこれらの課題を反転させるために、以下のコンセプトをもとにアラートの品質改善を進めることにしました。
「アラートが通知されたときにすぐに気づいて次のアクションを起こせるか」
以下でそれぞれの課題と解決に向けての具体の取り組みについてまとめていきます。
どのアラート通知チャンネルを見るべきかわからない
システムアラートに迅速に気づけるよう、Slack などのチャットツールに通知する設定をしていることが多いと思います。
BASE でも Slack にアラートを通知しています。しかし、これまでの運用の中で過去の組織体制に合わせて作成されたものや開発プロジェクト単位で作られたもの、さらには内容の重複するチャンネルなどが乱立した状態でした。そのため、「どのチャンネルを見ればよいのか」がとても分かりにくい状態に陥っていました。
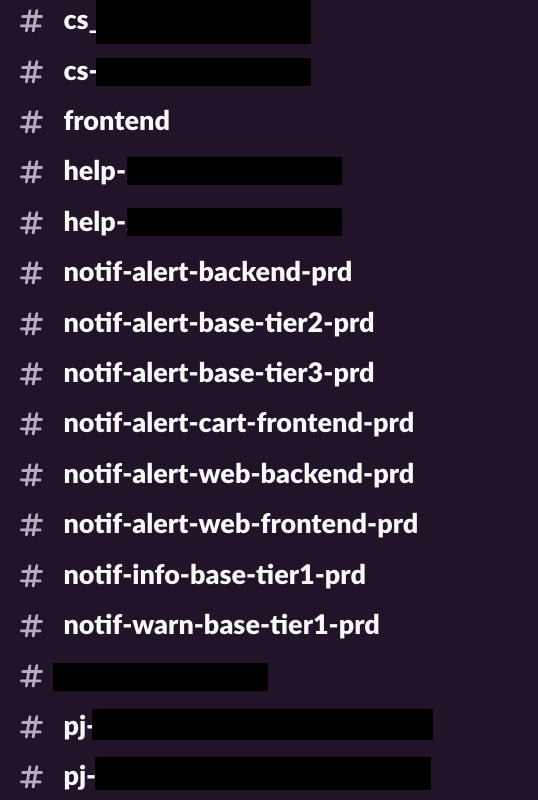
この課題を解決するため、まずはチャンネルの役割を整理し、以下に挙げる命名規則の策定を含めた再編を進めました。
チャンネルのprefix, suffix
チャンネルの検索性と視認性を向上させるため、prefix と suffix の命名規則を定めました。これにより、Slack 上で関連チャンネルがまとまって表示されるようになりました。
| 命名規則 | 役割 |
|---|---|
| チャンネル名の prefix | notif- |
| チャンネル名の suffix | 環境を表す -prd, -stg, -dev |
緊急度でチャンネルを分ける
通知の緊急度に応じてチャンネルを分けることで、即時対応が必要なアラートに集中しやすい構成としました。分類の基準は syslog の重大度レベルを参考にしています。
| チャンネルの prefix | 役割 |
|---|---|
| notif-alert- | 即時対応が必要なもの |
| notif-warn- | 即時対応は不要だが念の為通知しておきたいもの |
| notif-info- | プログラムの動作確認やデバッグのための情報を通知する(利用後の通知削除を推奨) |
サービスを重要度で分ける
サービスの重要度は、「BASE」の主要機能(決済やショップ管理画面)と社内向けの管理画面ではやはり異なります。そこで、サービスごとの重要度を Tier1 から Tier3 に分類し、重要なサービスの異常検知の確度を高められるようにしました。
| 重要度 | チャンネル作成方針 |
|---|---|
| Tier1 | サービス毎に alert レベルのチャンネルを作り通知する。warn, info レベルではチャンネルをまとめる。 |
| Tier2 | alert レベルのチャンネルをまとめる。warn, info レベルのチャンネルは必要に応じて作成する。 |
| Tier3 | alert レベルのチャンネルをまとめる。warn, info レベルのチャンネルは必要に応じて作成する。 |
監視ツール毎に通知チャンネルを分けない
BASE のアプリケーション開発チームでは、監視ツールとして主に Sentry と New Relic を利用しています。監視ツールごとに個別のチャンネルを設けると、確認すべきチャンネルが増え過ぎてしまい、重要な通知を見落とすリスクが高まります。そのため、全ての監視ツールからの通知を単一のチャンネルに集約し、通知の確認漏れを防ぐ工夫をしています。
再編の結果
これらの整理により、プロダクション環境向けの通知チャンネルを 21 から 8 に削減できました。チャンネル数はまだ減らせる余地がありつつも、アラートの確認先が明確になったことで、エンジニアの認知負荷を軽減できています。
通知が多すぎてどれが重要なアラートかわからない
チャンネルの役割や命名規則を整えたことでチャンネルを集約し見るべきチャンネルがわかりやすくなりました。その次に取り組んだのが、アラート数の削減です。チャンネルを集約したことも要因の 1 つですが、それ以前からアラートの数自体がそもそも多く、どれが重要なアラートかわからない状態が続いていました。
といってもアラート通知数を減らすには根本解決をするか、アラート通知設定を見直し通知されないようにするかしかありません。そこで以下の順番で取り組みを進めました。
- エラーを一気に減らした
- 週 1 回 1 時間の定例でアラート設定の見直しとエラー解消を進めた
エラーを一気に減らした
下の画像は、Tier1 に分類される重要サービスの Sentry のイシューの数を示しています。970 件ものイシューが積み重なっていて、チャンネルへのアラート通知も 1 日あたり 5〜15 件と頻発していました。さらに、同じエラーが繰り返し通知されることも多く、新規の重要アラートの識別が困難な状況でした。

この課題に対し、チームの有志メンバーが約 1 ヶ月間で 100 件近くのプルリクエストを作成し、エラーの根本的な解決とアラート設定の見直しを集中的に行いました。その結果、蓄積されていた Sentry の Issue を 970 件→0 件に削減できました。これにより、日々のアラート通知数も 1 日 2-3 件程度(ときには 0 件)に落ち着いています(進めてくれたメンバーの方には感謝しかありません)。このようにノイズが減ったことで、アラート検知をきっかけに緊急性が高い不具合を見つけることにもつながっています。
週1回1時間の定例でアラート設定の見直しとエラー解消を進めた
アラートを一気に減らすことができたため、次のステップとして日々新たに発生するアラートへの対応プロセスを確立させる必要がありました。緊急性の高いアラートについては発生時点で即座に確認・判断されるものの、緊急性が低いアラートはどうしても放置されがちです。これらは時間とともに蓄積され、さらに再発を繰り返すことでチャンネルのノイズとなってしまいます。
そこで取り組み始めたのが、週 1 回 1 時間のアラートの棚卸し会です。棚卸し会では Sentry や New Relic で未対応となっているアラートを確認し、解決方針を定めて開発チームのバックログに登録しています。また時には、この会の中でエラーの修正まで行う場合もあります。棚卸し会の取り組みを始めて約半年ほど経過しましたが、平均して週に 1-2 件のペースでエラーとアラート通知の削減を実現できています。
アラートの定期的な棚卸しについては以下のブログを参考にしました。ありがとうございました。
通知を受けたとしても何をしていいのかわからない
取り組みの最後は、アラート対応の効率化を目的とした 対応手順書(runbook) の整備です。
せっかくアラートを設定しているのですが、その意図や対応方法が不明確だったり、時間の経過で設定者も内容を忘れ迅速な対応が難しいケースも見られました。
そこで、アラート設定者含む誰もが素早く状況を把握し対応できるように、runbookの作成と運用を始めました。特に New Relic のアラートには runbook のリンクを登録できる機能があり、アラートから直接 runbook にアクセスできて便利です。
runbook には以下の項目を最低限含めるようにしています。
- アラートが発生したらまず最初にやること
- 詳しい調査手順
- 調査後の対応手順
- 困ったときにの連絡先
- 過去の対応履歴(Slack リンクなど)
ちなみに、runbook は GitHub に専用のリポジトリを作りその中に置いています。Notion などのドキュメント管理ツールよりも GitHub はリプレイスされることを想像しにくく、相対的に URL の寿命が長いと判断したためです。
まとめ
BASE のプロダクト開発チームでは、アラート品質を向上させるために以下の取り組みを 1 年かけて行ってきました。
- アラート通知チャンネルの役割整理と統廃合
- アラート通知数の削減
- runbook の作成
通知チャンネルの再編などはわかりやすい形で改善できた部分もあり、チームに勢いをつけるという意味でも一定の成果を出せたのではないかと考えています。
一方でアラート削減の取り組みについては改善が進んでいるのは一部のサービスに限られるなど、全体の進捗としては 4 合目くらいの感覚です。
まだまだ道半ばですがこれからも泥臭くアラート品質の向上に取り組んでいくことで、サービスの信頼性の向上につなげていけたらと考えています。
おわりに
BASE におけるサービスレベルマネジメントの取り組みは始まったばかりです。来年度も継続的に取り組んでいく予定です。
なお、BASE では現在エンジニアリングマネージャーの採用も積極的に行っております。エンジニアリングマネージャーとして一緒に頭を悩ませながらプロダクトを成長させていく仲間を募集しています。もし興味をもっていただいた方はぜひ 1 度カジュアルにお話させてください。 A-1.BASE_エンジニアリングマネージャー / BASE株式会社
最後まで読んでいただきありがとうございました。
明日は@miyachin_87さんの記事です。お楽しみに〜